Nein, hier geht es nicht um Musik, da wär ich wohl im falschen Forum ...
tl;dr Hier geht es um eine Beschreibung von Vibe Coding wie ich es sehe und was ich vor kurzem umgestellt habe, um den Region-Server zu optimieren. Observability, OpenTelemetry, Grafana Cloud sind Themen.
Vielleicht zuerst eine kleine Definition:
Vibe Coding ist ein relativ neuer Begriff in der Programmier-Community, der einen Programmierstil beschreibt, bei dem man sich mehr auf das "Gefühl" und den Flow verlässt als auf strenge Planung oder Best Practices.
Die Kernidee hinter Vibe Coding:
- Man schreibt Code intuitiv, ohne grosse Vorplanung oder Architektur-Überlegungen
- der Fokus liegt auf schnellem Experimentieren und "einfach mal machen"
- weniger Sorgen um perfekte Struktur, Dokumentation oder Tests
- Man lässt sich von der Stimmung und Kreativität des Moments leiten
Die Kernidee hinter Agentic Development:
- Fokus: KI-Agenten übernehmen ganze Entwicklungsaufgaben autonom
- Ansatz: "Ich delegiere komplexe Tasks an einen KI-Agenten"
- Kontrolle: Der Agent arbeitet selbstständiger - plant, implementiert, testet teilweise eigenständig
- Typisch: KI schreibt ganze Features, refactored Code, debuggt, nutzt Tools eigenständig
- Werkzeug: Spezialisierte KI-Agenten (wie Claude Code, Devin, Cursor mit Agent Mode)
Vibe Coding ist eine Arbeitsweise - ein lockerer, Flow-orientierter Stil, den man mit oder ohne KI praktizieren kann.
Agentic Development ist ein Delegationsmodell - man übergibt grössere Verantwortung an autonome KI-Systeme, die komplexere Aufgaben eigenständig lösen.
überschneidung
In der Praxis kombinieren viele Entwickler beides: Sie nutzen agentic tools (wie Claude Code), um sich auf den Vibe zu konzentrieren - also schnell Ideen umzusetzen, ohne sich in Details zu verlieren. Die KI übernimmt die "Denkarbeit" für Implementierungsdetails, während der Mensch im kreativen Flow bleibt.
Mein Vibe im OpenSim
Ich kenne die Architektur des Projekts mehr oder weniger. Ich weiss, was ich erzielen will (kleine Schritte). Dazu nutze ich eine Umgebung, welche mir viel Arbeit abnimmt.
Die beste Erfahrung habe ich mit Claude Code gemacht. Er will eine Änderung machen, zeigt mir dies an und ich entscheide, ob er loslegen soll. Nachteil von Claude Code. Kostet Geld. Aber ich kann den Pro-Plan von Claude nutzen. Kostet pro jahr etwa 160 Euro. Natürlich hab ich da nicht Tokens ohne Ende. Es ist mir schon oft passiert, dass ich eine Meldung kriege: Deine Token sind aufgebraucht, der Reset findet um 20:00 Uhr statt. Also Zwangspause bis 20:00 Uhr. Es existieren noch andere Modi die sind jedoch viiiiel teurer. Und Claude Code funktioniert nur mit Claude zusammen.
In letzter Zeit wird gerade OpenCode gehyped. Hat durchaus auch Vorteile. Es ist möglich beliebige Modelle zu nutzen auch kostenlose. OpenCode ist jedoch näher bei Agentic Development und ich werde da nicht warm damit, den Agent grössere Arbeiten machen zu lassen. Und um die Claude Modelle zu nutzen, brauch ich API Token. Mit OpenCode die Claude Pro Schnittstelle zu nutzen lief bis vor Kurzem, aber Anthropic hat dies nun unterbunden. Und API Token sind sehr teuer.
Vibe von Mistral existiert auch noch. Hat ebenfalls die Möglichkeit gratis Modelle zu nutzen. Ist vom Stil her näher an Claude Code. Und Mistral bietet einen gratis Zugang zu den eigenen Modellen. Begeisterung hält sich aber noch in Grenzen.
Let's do something
Eine Frage welche mich interessiert. Wann läuft ein OpenSim Region Server gut. Und wann nicht und wie sehe ich das. Observability ist das Zauberwort. Hier eine kleine Erklärung:
Observability ist die Fähigkeit, den internen Zustand eines Systems anhand seiner externen Ausgaben zu verstehen und zu analysieren. Der Begriff stammt ursprünglich aus der Kontrolltheorie, hat sich aber vor allem in der Software-Entwicklung und IT-Operations etabliert.
Die drei Säulen der Observability:
Logs – Detaillierte Ereignisaufzeichnungen, die beschreiben, was zu einem bestimmten Zeitpunkt passiert ist
Metrics – Numerische Messwerte über Zeit (z.B. CPU-Auslastung, Response Times, Fehlerraten)
Traces – Verfolgung von Requests durch verteilte Systeme hinweg
Logs habe ich. Kein Thema. Metrics fehlen mir. Klar kann ich mit einem Profiler rein, ist aber für den Betrieb zu heftig. Aber auch dazu gibt es eine Lösung:
OpenTelemetry (oft abgekürzt als OTel) ist ein Open-Source-Framework für Observability, das zum Standard für das Sammeln von Telemetriedaten aus Anwendungen geworden ist.
Was macht OpenTelemetry?
Es bietet eine einheitliche, herstellerneutrale Methode zum Instrumentieren, Generieren, Sammeln und Exportieren von Telemetriedaten (Traces, Metrics, Logs). Statt für jedes Observability-Tool eine eigene Integration zu bauen, verwendest du OpenTelemetry einmal und kannst dann flexibel zwischen verschiedenen Backend-Anbietern wechseln.
Backend-Anbieter also Systeme, welche die OpenTelemetry Daten sammeln und grafisch auswerten, gibt es einige. Kann man sich selber installieren. Jaeger und Zipkin kommen mir da in den Sinn. Die beiden sind spezialisiert auf Traces. Will ich aber im Moment noch nicht. Vorerst brauch ich Logs und Metrics.
Grafana resp. Grafana Cloud war dann die Lösung. Bei Grafana Labs kriegt man eine Grafana Cloud Instanz für Lau mit grosszügig bemessenem Storage. Schnell subscribed und nach 10 Minuten war dies eingerichtet.
Ok was brauche ich nun für OpenTelemetry in meinem Region-Server? Hab ich dann Claude Code gesagt, er solle mir doch bitte OpenTelemetry für Logs und Traces einbauen. Unter anderem kamen da diese Libraries neu in den Region-Server mit rein:
Code: Alles auswählen
dotnet add package OpenTelemetry
dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol
dotnet add package OpenTelemetry.Instrumentation.Http
Einen Region-Server zu bauen ist per Standard runprebuild.sh und compile.sh. Die Abhängigkeiten der Packages werden im prebuild.xml beschrieben usw. Leider funktioniert nur OpenSim mit diesem Prebuild Gedöns. Der Rest der Welt nutzt den NuGet Package Manager. Dieser Prebuild Mechanismus war mir schon lange ein Dorn im Auge. Die Wahrheit liegt in den csproj files und nicht in einem Prebuild XML. Entwicklungsumgebungen sind auf NuGet optimiert und dort ist die Wahrheit halt in den *.csproj files ( wie in Java in den *.pom files ).
Zusammen mit Claude Code war der Build Prozess recht rasch umgebaut. Die Schwierigkeit: Die Package-Verwaltung in OpenSim ist gelinde gesagt ein Desaster oder schlichtweg nicht existent. Da liegen *.dll herum in einer Version, welche gefühlt Jahrzehnte alt sind. Zu einigen DLL gibt es kein NuGet Package und woher sie kommen ist auch unklar. Deshalb haben liegen im Git des OpenSim auch noch dll rum, was eigentlich nicht die feine Art ist.
Egal damit lebe ich erst mal und nach einigen Iterationen war auch dieses Problem gelöst. Und dann Tadaaa:
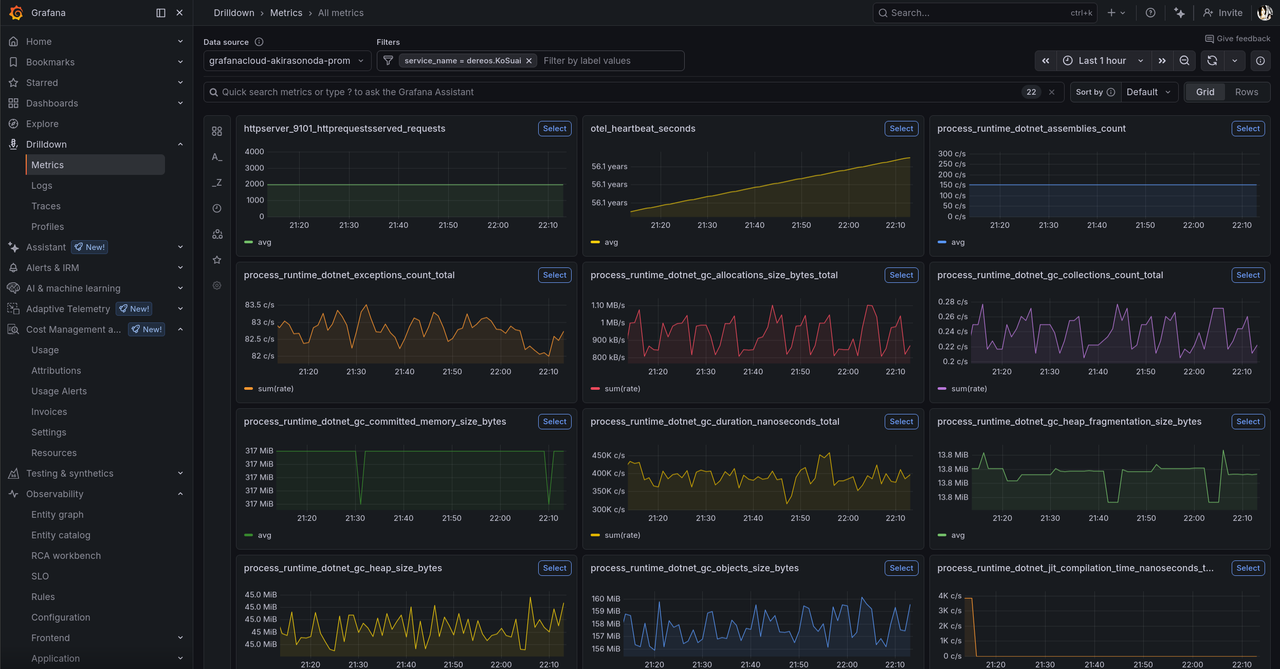
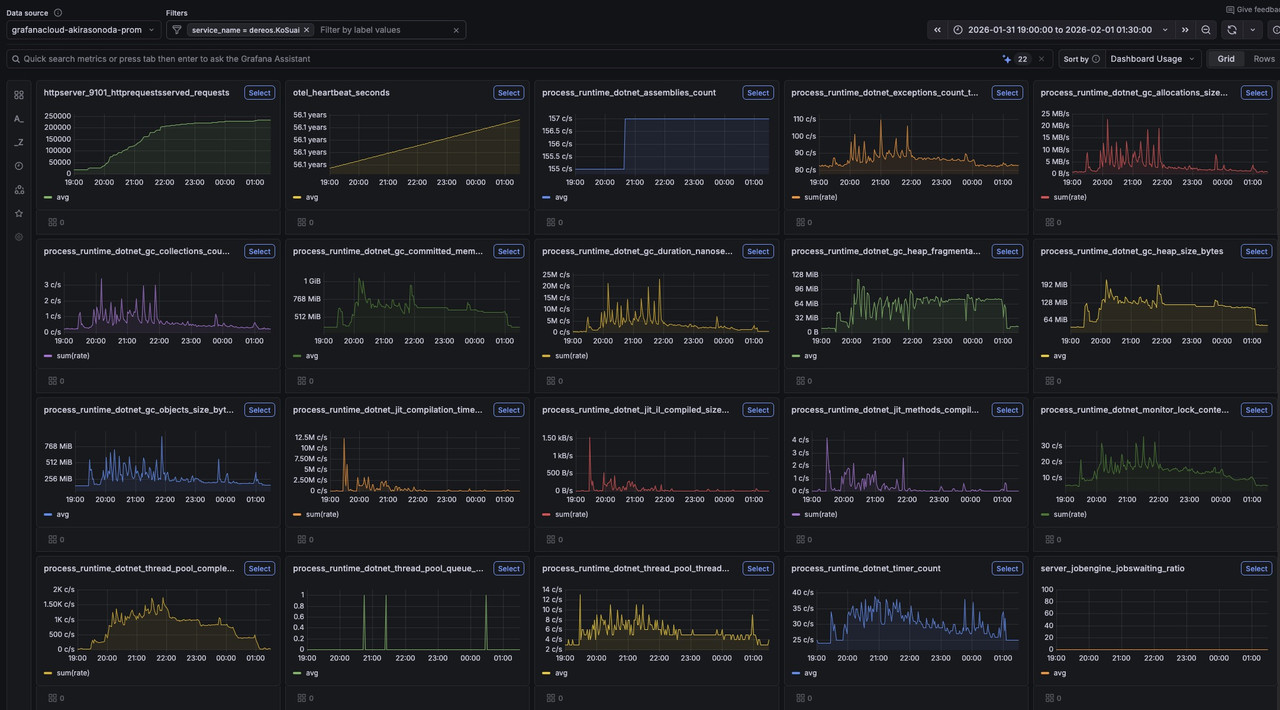
Vielleicht fällt auf: otel_heartbeat_seconds ist bei 56 Jahren und tendenz steigend. Da hat Claude Code noch was falsch gemacht. Er sendet nur die Timestamps ab Epoch (1.1.1970) und nicht die Differenz von zwei Timestamps. Muss ich ihm noch austreiben.
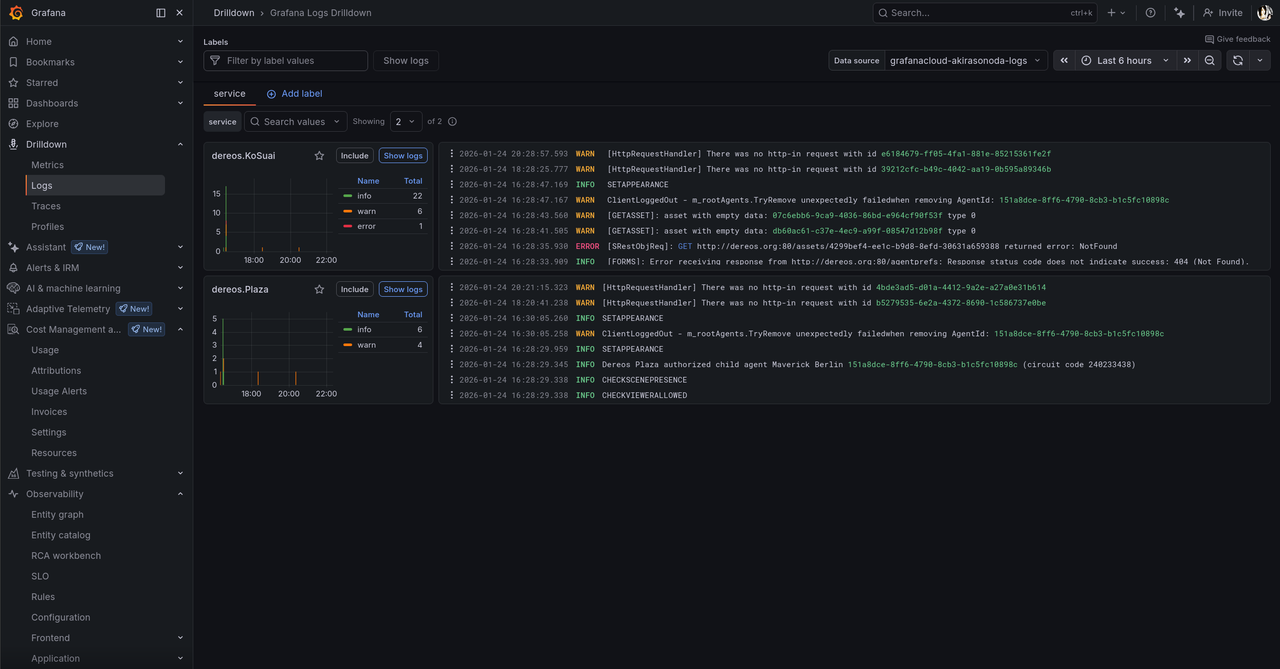
Find ich voll Cool. Logs und Metrics an einem Ort, zentral.
Fazit:
- Build System modernisiert (NuGet)
- OpenTelemetry Logs und Metrics eingebaut
- Zeilen codiert: 0
Liebe Grüsse
Akira